Valkey 并非严格意义上的键值存储,因为值可以是复杂的数据结构。然而,它具有一个外部键值外壳:在 API 级别,数据通过键名来寻址。可以说,从原生角度来看,Valkey 只提供主键访问。然而,由于 Valkey 是一个数据结构服务器,其能力可以用于索引,以创建各种类型的二级索引,包括复合(多列)索引。
本文档解释了如何使用以下数据结构在 Valkey 中创建索引
- 有序集合(Sorted sets)用于通过 ID 或其他数值字段创建二级索引。
- 具有字典序范围的有序集合(Sorted sets)用于创建更高级的二级索引、复合索引和图遍历索引。
- 集合(Sets)用于创建随机索引。
- 列表(Lists)用于创建简单的可迭代索引和最后 N 项索引。
在 Valkey 中实现和维护索引是一个高级主题,因此大多数需要对数据执行复杂查询的用户应该了解关系型存储是否更适合他们的需求。然而,通常情况下,特别是在缓存场景中,明确需要将索引数据存储到 Valkey 中,以加速需要某种形式索引才能执行的常见查询。
使用有序集合的简单数值索引
您可以使用 Valkey 创建的最简单的二级索引是使用有序集合数据类型,它是一种数据结构,表示一组按浮点数排序的元素,该浮点数是每个元素的分数(score)。元素按分数从最小到最大排序。
由于分数是双精度浮点数,使用原始有序集合构建的索引仅限于索引字段是给定范围内数字的情况。
构建此类索引的两个命令是 ZADD 和 ZRANGE,其中 BYSCORE 参数分别用于添加项和在指定范围内检索项。
例如,可以通过向有序集合添加元素来按年龄索引一组人名。元素将是人名,分数将是年龄。
ZADD myindex 25 Manuel
ZADD myindex 18 Anna
ZADD myindex 35 Jon
ZADD myindex 67 Helen
为了检索年龄在 20 到 40 岁之间的所有人,可以使用以下命令
ZRANGE myindex 20 40 BYSCORE
1) "Manuel"
2) "Jon"
通过使用 ZRANGE 的 WITHSCORES 选项,还可以获取与返回元素关联的分数。
ZCOUNT 命令可用于检索给定范围内元素的数量,而无需实际获取元素,这也很实用,特别是考虑到该操作以对数时间执行,无论范围大小如何。
范围可以是包含或不包含边界的,请参阅 ZRANGE 命令文档以获取更多信息。
注意:使用带有 BYSCORE 和 REV 参数的 ZRANGE 命令,可以以反向顺序查询范围,这在数据以给定方向(升序或降序)索引但我们希望以相反方式检索信息时通常很有用。
使用对象 ID 作为关联值
在上面的例子中,我们将名称与年龄关联起来。然而,通常我们可能希望索引存储在其他地方的某个对象的字段。除了直接使用有序集合值来存储与索引字段关联的数据外,还可以只存储对象的 ID。
例如,我可能有一些代表用户的哈希(Hashes)。每个用户都由一个单一的键表示,可以通过 ID 直接访问
HSET user:1 id 1 username antirez ctime 1444809424 age 38
HSET user:2 id 2 username maria ctime 1444808132 age 42
HSET user:3 id 3 username jballard ctime 1443246218 age 33
如果我想创建一个索引来按年龄查询用户,我可以这样做
ZADD user.age.index 38 1
ZADD user.age.index 42 2
ZADD user.age.index 33 3
这次,有序集合中与分数关联的值是对象的 ID。因此,一旦我使用带有 BYSCORE 参数的 ZRANGE 查询索引,我还必须使用 HGETALL 或类似命令检索我需要的信息。显而易见的优势是,只要我们不更改索引字段,对象就可以更改而无需触及索引。
在接下来的示例中,我们几乎总是使用 ID 作为与索引关联的值,因为这通常是更稳健的设计,但也有少数例外情况。
更新简单有序集合索引
我们经常索引随时间变化的事物。在上面的例子中,用户的年龄每年都在变化。在这种情况下,使用出生日期作为索引而不是年龄本身会更有意义,但也有其他情况,我们只是希望某个字段不时更改,并且索引能够反映这种更改。
ZADD 命令使更新简单索引成为一项非常简单的操作,因为以不同的分数和相同的值重新添加一个元素将简单地更新分数并将元素移动到正确的位置,因此,如果用户 antirez 变成了 39 岁,为了更新表示该用户的哈希数据以及索引中的数据,我们需要执行以下两个命令
HSET user:1 age 39
ZADD user.age.index 39 1
该操作可以封装在 MULTI/EXEC 事务中,以确保两个字段都更新或都不更新。
将多维数据转换为线性数据
用有序集合创建的索引只能索引单个数值。因此,您可能认为不可能使用这种索引来索引具有多个维度的事物,但实际上并非总是如此。如果您能有效地将多维事物线性表示,那么通常可以使用简单的有序集合进行索引。
例如,Valkey 地理空间索引 API 使用有序集合,通过一种称为 Geo hash(地理哈希)的技术,根据经纬度索引地点。有序集合的分数表示经度和纬度的交替位,这样我们将有序集合的线性分数映射到地球表面的许多小方格中。通过执行 8+1 样式(中心加邻近)搜索,可以按半径检索元素。
分数的限制
有序集合元素的分数是双精度浮点数。这意味着它们可以表示具有不同误差的不同小数或整数值,因为它们内部使用指数表示。然而,对于索引目的而言,有趣的是分数总是能够无误差地表示 -9007199254740992 到 9007199254740992 之间的数字,即 -/+ 2^53。
当表示更大的数字时,您需要一种不同形式的索引,它能够以任意精度索引数字,这称为字典序索引。
字典序索引
有序集合有一个有趣的特性。当元素以相同的分数添加时,它们会根据字典序排序,使用 memcmp() 函数将字符串作为二进制数据进行比较。
对于不了解 C 语言和 memcmp 函数的人来说,这意味着相同分数的元素是通过逐字节比较其原始字节值来排序的。如果第一个字节相同,则检查第二个字节,依此类推。如果两个字符串的公共前缀相同,则较长的字符串被认为是较大的一个,因此“foobar”大于“foo”。
有 ZRANGE 和 ZLEXCOUNT 等命令,它们能够以字典序方式查询和计数范围,前提是它们与所有元素具有相同分数的有序集合一起使用。
这个 Valkey 特性基本等同于 b-tree 数据结构,后者常用于传统数据库中实现索引。如您所料,正因为如此,可以使用这种 Valkey 数据结构来实现相当高级的索引。
在我们深入使用字典序索引之前,让我们先了解有序集合在这种特殊操作模式下的行为。由于我们需要添加分数相同的元素,我们将始终使用特殊的零分数。
ZADD myindex 0 baaa
ZADD myindex 0 abbb
ZADD myindex 0 aaaa
ZADD myindex 0 bbbb
从有序集合中获取所有元素立即显示它们是按字典序排序的。
ZRANGE myindex 0 -1
1) "aaaa"
2) "abbb"
3) "baaa"
4) "bbbb"
现在我们可以使用带有 BYLEX 参数的 ZRANGE 命令来执行范围查询。
ZRANGE myindex [a (b BYLEX
1) "aaaa"
2) "abbb"
请注意,在范围查询中,我们用特殊字符 [ 和 ( 为标识范围的 min 和 max 元素添加了前缀。这些前缀是强制性的,它们指定范围内的元素是包含性的还是排他性的。因此,范围 [a (b 意味着给我所有按字典序介于 a(包含)和 b(不包含)之间的元素,也就是所有以 a 开头的元素。
还有两个特殊字符表示无限负字符串和无限正字符串,它们是 - 和 +。
ZRANGE myindex [b + BYLEX
1) "baaa"
2) "bbbb"
基本上就是这样。让我们看看如何使用这些特性来构建索引。
第一个例子:自动补全
索引的一个有趣应用是自动补全。自动补全是指当您开始在搜索引擎中输入查询时,用户界面会预测您可能正在输入的内容,提供以相同字符开头的常见查询。
自动补全的一种简单方法是,将我们从用户那里获得的每一个查询都添加到索引中。例如,如果用户搜索 banana,我们将只执行
ZADD myindex 0 banana
每个遇到的搜索查询都以此类推。然后,当我们想要补全用户输入时,我们使用带有 BYLEX 参数的 ZRANGE 命令执行范围查询。想象用户在搜索表单中输入“bit”,我们想提供以“bit”开头的可能搜索关键词。我们向 Valkey 发送这样的命令
ZRANGE myindex "[bit" "[bit\xff" BYLEX
基本上,我们使用用户当前正在输入的字符串作为范围的开始,以及该字符串加上一个设置为 255 的尾随字节(在示例中是 \xff)作为范围的结束。通过这种方式,我们获取所有以用户正在输入的字符串开头的字符串。
请注意,我们不希望返回太多项,因此可以使用 LIMIT 选项来减少结果数量。
加入频率考量
上述方法有点简单,因为所有用户搜索都以相同的方式处理。在实际系统中,我们希望根据字符串的频率来完成字符串:非常流行的搜索将以更高的概率被推荐,而很少输入的搜索字符串则相反。
为了实现一种依赖于频率,同时通过清除不再流行的搜索来自动适应未来输入的机制,我们可以使用一个非常简单的流式算法。
首先,我们修改索引,以便不仅存储搜索词,还存储与该词关联的频率。因此,我们不再只添加 banana,而是添加 banana:1,其中 1 是频率。
ZADD myindex 0 banana:1
我们还需要逻辑来在搜索词已存在于索引中时递增索引,所以我们实际上会这样做
ZRANGE myindex "[banana:" + BYLEX LIMIT 0 1
1) "banana:1"
如果存在,这将返回 banana 的单个条目。然后我们可以递增关联频率并发送以下两个命令
ZREM myindex 0 banana:1
ZADD myindex 0 banana:2
请注意,由于可能存在并发更新,上述三个命令应通过 Lua 脚本发送,以便 Lua 脚本能够原子地获取旧计数并以递增的分数重新添加项。
因此,结果是,每当用户搜索 banana 时,我们的条目都会得到更新。
还有更多:我们的目标是只保留被频繁搜索的项。因此我们需要某种形式的清除机制。当我们实际查询索引以完成用户输入时,我们可能会看到这样的情况
ZRANGE myindex "[banana:" + BYLEX LIMIT 0 10
1) "banana:123"
2) "banaooo:1"
3) "banned user:49"
4) "banning:89"
显然,例如没有人搜索“banaooo”,但该查询只执行了一次,所以我们最终将其呈现给用户。
我们可以这样做。从返回的项中,我们随机选择一个,将其分数减一,并以新分数重新添加。但是,如果分数达到 0,我们只需从列表中移除该项。您可以使用更高级的系统,但其思想是,从长远来看,索引将包含热门搜索,如果热门搜索随时间变化,它将自动适应。
该算法的一个改进是根据条目的权重来选择列表中的条目:分数越高,被选中以减少其分数或驱逐的可能性就越小。
标准化字符串以处理大小写和重音
在自动补全示例中,我们总是使用小写字符串。然而,现实比这复杂得多:语言有大写名称、重音符号等等。
解决这些问题的一种简单方法是实际规范化用户搜索的字符串。无论用户搜索“Banana”、“BANANA”还是“Ba'nana”,我们都可以将其转换为“banana”。
然而,有时我们可能希望向用户展示原始输入的项,即使我们为了索引而对字符串进行了标准化。为了做到这一点,我们所做的是改变索引的格式,以便不再只存储 term:frequency,而是存储 normalized:frequency:original,如下例所示
ZADD myindex 0 banana:273:Banana
基本上,我们添加另一个字段,该字段将只提取并用于可视化。范围将始终使用标准化字符串进行计算。这是一个具有多种应用的常见技巧。
在索引中添加辅助信息
当直接使用有序集合时,每个对象有两个不同的属性:分数(我们用作索引)和关联值。然而,当使用字典序索引时,分数始终设置为 0,并且基本上根本不使用。我们只剩下一个字符串,即元素本身。
就像我们在之前的自动补全示例中所做的那样,我们仍然能够使用分隔符存储关联数据。例如,我们使用冒号来添加频率和用于自动补全的原始词。
一般来说,我们可以向索引键添加任何类型的关联值。为了使用字典序索引来实现一个简单的键值存储,我们只需将条目存储为 key:value
ZADD myindex 0 mykey:myvalue
并用以下方式搜索键
ZRANGE myindex [mykey: + BYLEX LIMIT 0 1
1) "mykey:myvalue"
然后我们提取冒号后面的部分来检索值。然而,在这种情况下需要解决的一个问题是冲突。冒号字符本身可能是键的一部分,因此必须选择它以确保永远不会与我们添加的键冲突。
由于 Valkey 中的字典序范围是二进制安全的,您可以使用任何字节或任何字节序列。但是,如果您收到不受信任的用户输入,最好使用某种形式的转义,以确保分隔符永远不会成为键的一部分。
例如,如果您使用两个空字节作为分隔符 "\0\0",您可能希望始终将字符串中的空字节转义为两个字节序列。
数字填充
字典序索引可能看起来只适用于索引字符串的问题。实际上,使用这种索引来对任意精度数字进行索引非常简单。
在 ASCII 字符集中,数字按 0 到 9 的顺序出现,因此如果我们用前导零左填充数字,结果是将其作为字符串比较时将按其数值排序。
ZADD myindex 0 00324823481:foo
ZADD myindex 0 12838349234:bar
ZADD myindex 0 00000000111:zap
ZRANGE myindex 0 -1
1) "00000000111:zap"
2) "00324823481:foo"
3) "12838349234:bar"
我们有效地使用了一个可以任意大的数值字段创建了一个索引。这对于任何精度的浮点数也有效,只要我们确保数值部分左填充前导零,小数部分右填充后导零,如下列数字所示
01000000000000.11000000000000
01000000000000.02200000000000
00000002121241.34893482930000
00999999999999.00000000000000
使用二进制形式的数字
以十进制存储数字可能会占用太多内存。另一种方法是直接以二进制形式存储数字,例如 128 位整数。然而,为了使其工作,您需要以大端格式存储数字,以便最高有效字节存储在最低有效字节之前。这样,当 Valkey 使用 memcmp() 比较字符串时,它将有效地按其值对数字进行排序。
请记住,以二进制格式存储的数据对于调试来说可观察性较低,更难解析和导出。因此,这无疑是一种权衡。
复合索引
到目前为止,我们探索了索引单个字段的方法。然而,我们都知道 SQL 存储能够使用多个字段创建索引。例如,我可以在一个非常大的商店中按房间号和价格索引产品。
我需要运行查询来检索给定房间内具有给定价格范围的所有产品。我可以按照以下方式索引每个产品
ZADD myindex 0 0056:0028.44:90
ZADD myindex 0 0034:0011.00:832
这里字段是 room:price:product_id。为简单起见,我在示例中仅使用了四位数字填充。辅助数据(产品 ID)不需要任何填充。
有了这样的索引,获取房间 56 中价格在 10 到 30 美元之间的所有产品变得非常容易。我们只需运行以下命令
ZRANGE myindex [0056:0010.00 [0056:0030.00 BYLEX
上述称为复合索引。其有效性取决于字段的顺序和我想要运行的查询。例如,上述索引无法有效地用于获取所有具有特定价格范围的产品,而不考虑房间号。然而,我可以使用主键来运行不考虑价格的查询,例如给我房间 44 中的所有产品。
复合索引功能非常强大,用于传统存储以优化复杂查询。在 Valkey 中,它们既可以用于实现传统数据存储中数据的超快速内存 Valkey 索引,也可以直接索引 Valkey 数据。
更新字典序索引
字典序索引中的索引值可能会变得相当复杂,并且从我们存储的对象信息中重建起来既困难又缓慢。因此,一种简化索引处理的方法(以牺牲更多内存为代价)是,除了表示索引的有序集合之外,还使用一个哈希表将对象 ID 映射到当前的索引值。
因此,例如,当我们索引时,我们也会添加到哈希表
MULTI
ZADD myindex 0 0056:0028.44:90
HSET index.content 90 0056:0028.44:90
EXEC
这并非总是必需的,但它简化了更新索引的操作。为了移除我们为对象 ID 90 索引的旧信息,无论对象的当前字段值如何,我们只需通过对象 ID 检索哈希值,并在有序集合视图中对其执行 ZREM。
使用六边形存储(Hexastore)表示和查询图
复合索引的一个很酷的特点是它们方便用于表示图,使用一种称为 Hexastore(六边形存储)的数据结构。
六边形存储提供了一种表示对象之间关系的方法,由一个主语(subject)、一个谓语(predicate)和一个宾语(object)组成。对象之间的一个简单关系可以是
antirez is-friend-of matteocollina
为了表示这种关系,我可以在我的字典序索引中存储以下元素
ZADD myindex 0 spo:antirez:is-friend-of:matteocollina
请注意,我用字符串 spo 作为我的项的前缀。这意味着该项表示主语、谓语、宾语关系。
我可以为相同的关系添加另外 5 个条目,但顺序不同
ZADD myindex 0 sop:antirez:matteocollina:is-friend-of
ZADD myindex 0 ops:matteocollina:is-friend-of:antirez
ZADD myindex 0 osp:matteocollina:antirez:is-friend-of
ZADD myindex 0 pso:is-friend-of:antirez:matteocollina
ZADD myindex 0 pos:is-friend-of:matteocollina:antirez
现在事情变得有趣了,我可以通过多种不同方式查询图。例如,antirez 的所有朋友都是谁?
ZRANGE myindex "[spo:antirez:is-friend-of:" "[spo:antirez:is-friend-of:\xff" BYLEX
1) "spo:antirez:is-friend-of:matteocollina"
2) "spo:antirez:is-friend-of:wonderwoman"
3) "spo:antirez:is-friend-of:spiderman"
或者,antirez 和 matteocollina 之间所有关系中,第一个是主语,第二个是宾语的关系有哪些?
ZRANGE myindex "[sop:antirez:matteocollina:" "[sop:antirez:matteocollina:\xff" BYLEX
1) "sop:antirez:matteocollina:is-friend-of"
2) "sop:antirez:matteocollina:was-at-conference-with"
3) "sop:antirez:matteocollina:talked-with"
通过组合不同的查询,我可以提出一些复杂的问题。例如:所有喜欢啤酒、住在巴塞罗那、并且也被 matteocollina 视为朋友的朋友是谁? 为了获取这些信息,我首先执行一个 spo 查询来找到所有与我成为朋友的人。然后,对于获得的每个结果,我执行一个 spo 查询来检查他们是否喜欢啤酒,移除那些找不到此关系的人。我再次按城市进行筛选。最后,我对获得的结果列表执行一个 ops 查询,以找出哪些人被 matteocollina 视为朋友。
务必查看 Matteo Collina 关于 Levelgraph 的幻灯片,以便更好地理解这些想法。
多维索引
一种更复杂的索引类型是允许您同时查询两个或更多变量的特定范围的索引。例如,我可能有一个表示人员年龄和薪水的数据集,并且我想要检索所有年龄在 50 到 55 岁之间且薪水在 70000 到 85000 之间的人。
此查询可以使用多列索引执行,但这要求我们先选择第一个变量,然后扫描第二个变量,这意味着我们可能需要做比所需更多的工作。可以使用不同的数据结构执行涉及多个变量的此类查询。例如,有时会使用多维树,如 k-d 树或 r-树。这里我们将描述一种将数据索引到多个维度的不同方式,使用一种表示技巧,允许我们使用 Valkey 字典序范围以非常高效的方式执行查询。
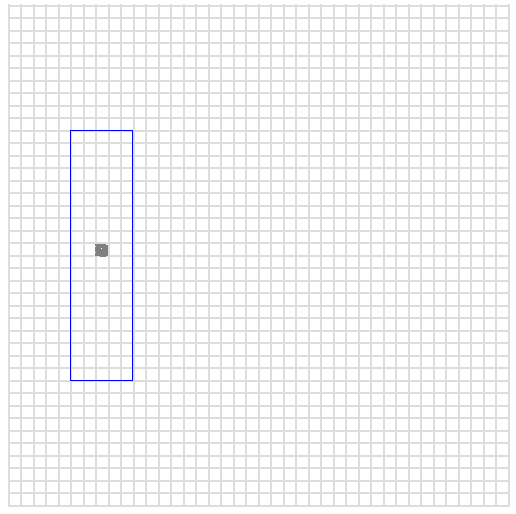
假设我们在空间中有一些点,它们代表我们的数据样本,其中 x 和 y 是我们的坐标。两个变量的最大值都是 400。
在下图中,蓝色方框代表我们的查询。我们想要所有 x 在 50 到 100 之间,且 y 在 100 到 300 之间的点。
为了表示使这类查询快速执行的数据,我们首先用 0 填充数字。例如,假设我们想将点 10,25 (x,y) 添加到我们的索引中。考虑到示例中的最大范围是 400,我们只需填充到三位数字,因此我们得到
x = 010
y = 025
现在我们要做的就是交错排列数字,取 x 的最左边数字,然后是 y 的最左边数字,依此类推,以创建一个单一的数字
001205
这是我们的索引,但是为了更轻松地重建原始表示(如果需要,会牺牲空间),我们还可以将原始值作为额外列添加
001205:10:25
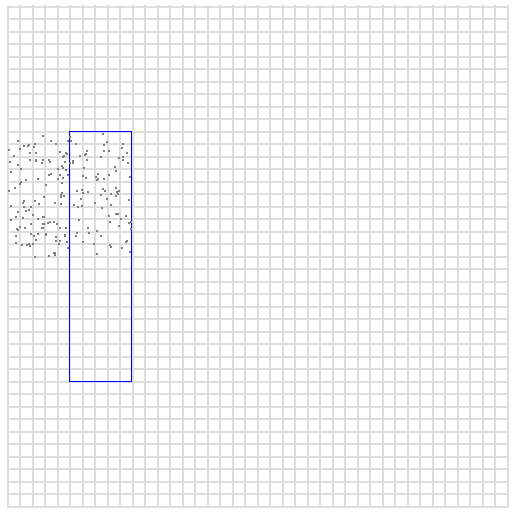
现在,让我们来探讨这种表示方法及其在范围查询中的用处。例如,我们取蓝色方框的中心,它位于 x=75 和 y=200。我们可以像之前一样通过交错数字来编码这个数字,得到
027050
如果我们分别用 00 和 99 替换最后两位数字会发生什么?我们得到一个字典序连续的范围
027000 to 027099
这映射到一个方格,表示 x 变量在 70 到 79 之间,y 变量在 200 到 209 之间的所有值。为了识别这个特定区域,我们可以在该区间内写入随机点。
因此,上述字典序查询使我们能够轻松地查询图中特定方格内的点。然而,该方格可能对于我们正在搜索的盒子来说太小,因此需要太多的查询。所以我们可以做同样的事情,但不是用 00 和 99 替换最后两位数字,而是替换最后四位数字,得到以下范围
020000 029999
这次,该范围表示 x 在 0 到 99 之间,y 在 200 到 299 之间的所有点。在此区间内绘制随机点可以向我们展示这个更大的区域。
所以现在我们的区域对于我们的查询来说太大了,而且我们的搜索框仍然没有完全包含在内。我们需要更细的粒度,但我们可以通过将数字表示为二进制形式轻松实现。这一次,当我们替换数字时,我们得到的方格不再是十倍大,而只是两倍大。
我们的数字的二进制形式(假设每个变量只需要 9 位,以便表示最大值为 400 的数字)将是
x = 75 -> 001001011
y = 200 -> 011001000
因此,通过交错数字,我们在索引中的表示将是
000111000011001010:75:200
让我们看看当我们用 0 和 1 替换交错表示中的最后 2、4、6、8... 位时,我们的范围是什么
2 bits: x between 74 and 75, y between 200 and 201 (range=2)
4 bits: x between 72 and 75, y between 200 and 203 (range=4)
6 bits: x between 72 and 79, y between 200 and 207 (range=8)
8 bits: x between 64 and 79, y between 192 and 207 (range=16)
依此类推。现在我们确实有了更好的粒度!正如您所看到的,从索引中替换 N 位会给我们边长为 2^(N/2) 的搜索框。
所以我们要做的是检查搜索框较小的维度,并找到该数字最接近的二次幂。我们的搜索框是从 50,100 到 100,300,因此它的宽度是 50,高度是 200。我们取两者中较小的一个,50,并检查最接近的二次幂,即 64。64 是 2^6,所以我们将使用通过替换交错表示中最后 12 位(从而最终只替换每个变量的 6 位)获得的索引。
然而,单个方格可能无法覆盖我们所有的搜索范围,所以我们可能需要更多。我们所做的是从搜索框的左下角(即 50,100)开始,并通过将每个数字的最后 6 位替换为 0 来找到第一个范围。然后我们对右上角做同样的操作。
通过两个简单的嵌套 for 循环,我们只递增有效位,就能找到这两个点之间的所有方格。对于每个方格,我们将这两个数字转换为我们的交错表示,并使用转换后的表示作为开始,以及相同的表示但最后 12 位都置为 1 作为结束范围来创建范围。
对于找到的每个方格,我们执行查询并获取其中的元素,然后移除搜索框外的元素。
将其转化为代码很简单。这里是一个 Ruby 示例
def spacequery(x0,y0,x1,y1,exp)
bits=exp*2
x_start = x0/(2**exp)
x_end = x1/(2**exp)
y_start = y0/(2**exp)
y_end = y1/(2**exp)
(x_start..x_end).each{|x|
(y_start..y_end).each{|y|
x_range_start = x*(2**exp)
x_range_end = x_range_start | ((2**exp)-1)
y_range_start = y*(2**exp)
y_range_end = y_range_start | ((2**exp)-1)
puts "#{x},#{y} x from #{x_range_start} to #{x_range_end}, y from #{y_range_start} to #{y_range_end}"
# Turn it into interleaved form for ZRANGE query.
# We assume we need 9 bits for each integer, so the final
# interleaved representation will be 18 bits.
xbin = x_range_start.to_s(2).rjust(9,'0')
ybin = y_range_start.to_s(2).rjust(9,'0')
s = xbin.split("").zip(ybin.split("")).flatten.compact.join("")
# Now that we have the start of the range, calculate the end
# by replacing the specified number of bits from 0 to 1.
e = s[0..-(bits+1)]+("1"*bits)
puts "ZRANGE myindex [#{s} [#{e]: BYLEX"
}
}
end
spacequery(50,100,100,300,6)
虽然这并非显而易见的简单,但这是一种非常有用的索引策略,未来可能以原生方式在 Valkey 中实现。目前,好消息是这种复杂性可以很容易地封装到一个库中,该库可用于执行索引和查询。此类库的一个例子是 Redimension,这是一个概念验证的 Ruby 库,它使用此处描述的技术在 Valkey 中索引 N 维数据。
带有负数或浮点数的多维索引
表示负值的最简单方法是使用无符号整数,并使用偏移量表示它们,这样当您索引时,在将数字转换为索引表示之前,您会加上较小负整数的绝对值。
对于浮点数,最简单的方法可能是通过将整数乘以一个与您希望保留的小数点后位数成比例的 10 的幂来将它们转换为整数。
非范围索引
到目前为止,我们检查了适用于按范围或按单个项目查询的索引。然而,其他 Valkey 数据结构,如集合(Sets)或列表(Lists),也可以用于构建其他类型的索引。它们非常常用,但我们可能不总是意识到它们实际上是一种索引形式。
例如,我可以将对象 ID 索引到集合(Set)数据类型中,以便通过 SRANDMEMBER 使用获取随机元素操作来检索一组随机对象。集合还可以用于检查是否存在,当所有我需要的是测试给定项目是否存在或者是否具有单个布尔属性时。
类似地,列表(Lists)可以用于按固定顺序索引项目。我可以将所有项目添加到列表中,并使用相同的键名作为源和目标,通过 RPOPLPUSH 旋转列表。这在我想以相同的顺序一遍又一遍地永久处理给定的一组项目时非常有用。想象一下需要定期刷新本地副本的 RSS 订阅系统。
另一个与 Valkey 常用流行索引是限制列表(capped list),其中项目通过 LPUSH 添加,并通过 LTRIM 修剪,以创建一个仅包含最新 N 个遇到项目的视图,并保持它们被看到的顺序。
索引不一致性
保持索引更新可能具有挑战性,在数月或数年内,可能会因为软件错误、网络分区或其他事件而导致不一致性。
可以使用不同的策略。如果索引数据在 Valkey 之外,读修复(read repair)可能是一个解决方案,即在请求数据时以惰性方式修复数据。当我们索引存储在 Valkey 本身的数据时,可以使用 SCAN 系列命令来验证、更新或从头开始增量重建索引。