
解锁百万 RPS:体验 Valkey 三倍速度提升 - 第二部分
在本博客的第一部分中,我们描述了如何将几乎所有 I/O 操作卸载到 I/O 线程,从而在主线程中释放更多 CPU 周期来执行命令。当我们分析主线程的执行情况时,发现相当一部分时间都花在了等待外部内存上。这并不完全令人惊讶,因为在访问随机键时,在处理器缓存中找到该键的概率相对较低。考虑到外部内存访问延迟大约是 L1 缓存的 50 倍,很明显,尽管显示 100% 的 CPU 利用率,但主进程大部分时间都在“等待”。在本博客中,我们将描述我们一直使用的技术,以增加并行内存访问的数量,从而减少外部内存延迟对性能的影响。
推测执行与链表
推测执行是现代处理器使用的一种性能优化技术,处理器会猜测条件操作的结果并提前并行执行后续指令。动态数据结构,例如链表和搜索树,相对于静态数据结构具有许多优点:它们节省内存消耗,提供快速插入和删除机制,并且可以高效地调整大小。然而,一些动态数据结构有一个主要缺点:它们阻碍了处理器对未来可能并行执行的内存加载指令进行推测的能力。这种缺乏并发性的问题在非常大的动态数据结构中尤为突出,因为大多数指针访问都会导致高延迟的外部内存访问。
在本博客中,将介绍内存访问分摊(Memory Access Amortization)这一有助于推测执行以提高性能的方法,以及它在 Valkey 中的应用。该方法的基本思想是,通过交错执行访问随机内存位置的操作,可以比串行执行它们获得显著更好的性能。
为了描述我们试图解决的问题,请考虑以下函数,该函数接收一个链表数组并返回所有链表中值的总和
unsigned long sequentialSum(size_t arr_size, list **la) {
list *lp;
unsigned long res = 0;
for (int i = 0; i < arr_size; i++) {
lp = la[i];
while (lp) {
res += lp->val;
lp = lp->next;
}
}
return res;
}
在 ARM 处理器 (Graviton 3) 上,对包含 1000 万个元素的 16 个链表数组执行此函数大约需要 20.8 秒。现在考虑以下替代实现,它不是单独扫描链表,而是交错执行链表扫描
unsigned long interleavedSum(size_t arr_size, list **la) {
list **lthreads = malloc(arr_size * sizeof(list *));
unsigned long res = 0;
int n = arr_size;
for (int i = 0; i < arr_size; i++) {
lthreads[i] = la[i];
if (lthreads[i] == NULL)
n--;
}
while(n) {
for (int i = 0; i < arr_size; i++) {
if (lthreads[i] == NULL)
continue;
res += lthreads[i]->val;
lthreads[i] = lthreads[i]->next;
if (lthreads[i] == NULL)
n--;
}
}
free(lthreads);
return res;
}
使用与之前描述相同的输入运行此新版本所需时间不到 2 秒,实现了 10 倍的速度提升!这一显著改进的解释在于处理器的推测执行能力。在链表的标准顺序遍历中(如函数的第一个版本所示),处理器无法“推测”未来的内存访问指令。这种限制在大列表上变得尤为昂贵,因为每个指针访问很可能导致昂贵的外部内存访问。相比之下,交错列表遍历的替代实现允许处理器并行发出更多内存访问。通过分摊,这导致了内存访问延迟的整体降低。
增加并行内存访问量的一种方法是添加预取指令。将
if (lthreads[i] == NULL)
n--;
替换为
if (lthreads[i])
__builtin_prefetch(lthreads[i]);
else
n--;
将执行时间进一步缩短到 1.8 秒。
回到 Valkey
在第一部分中,我们描述了如何更新现有的 I/O 线程实现以增加并行性,并将主线程执行的 I/O 操作量降到最低。事实上,我们观察到每秒请求数有所增加,达到每秒 780K 个 SET 命令。分析执行情况显示,Valkey 的主线程将其超过 40% 的时间花费在一个函数中:lookupKey,其目标是在 Valkey 的主字典中查找命令键。该字典实现为一个简单的链式哈希表,如下图所示: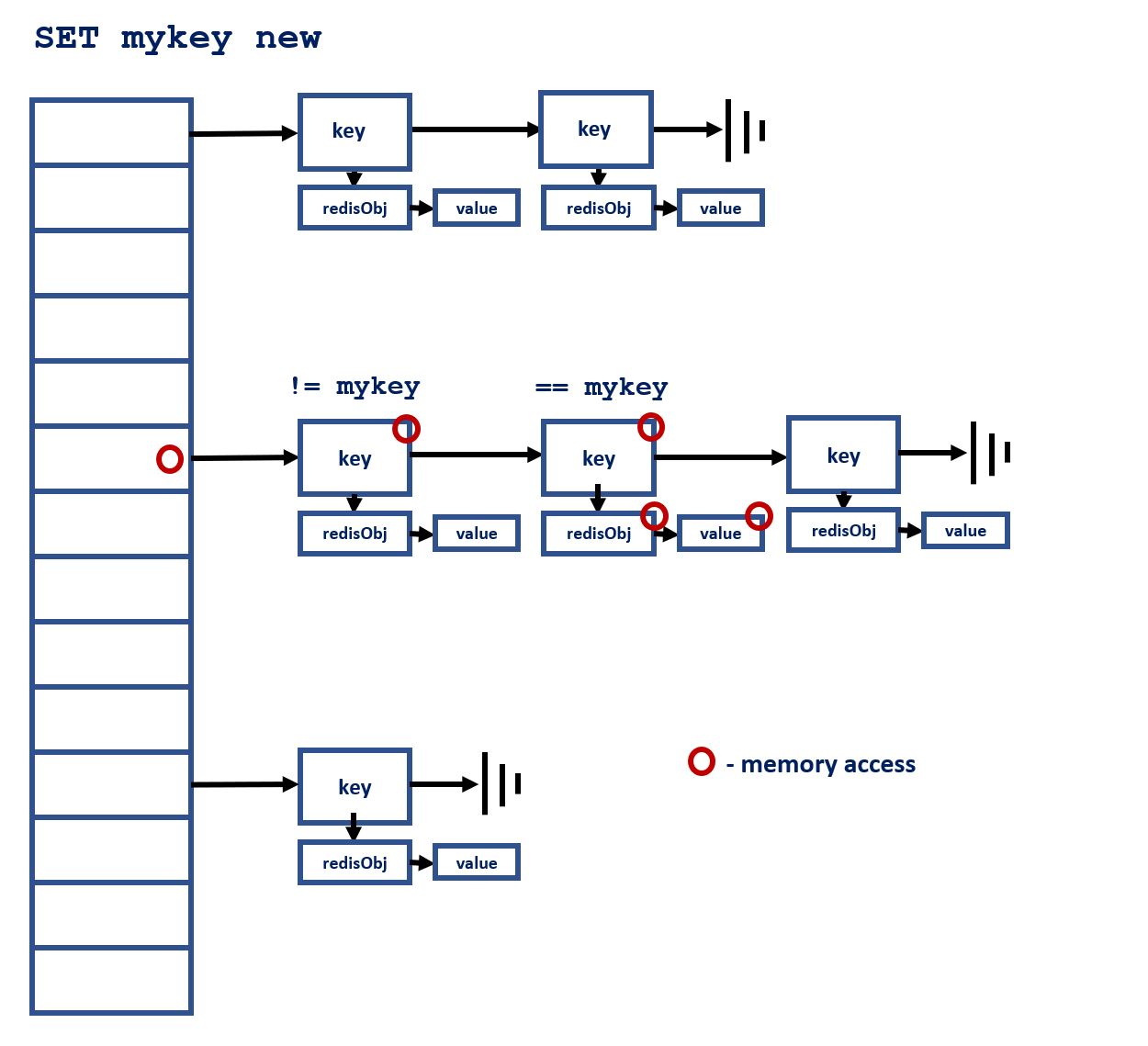 在足够大的键集上,搜索字典时访问的几乎每个内存地址都不会在任何处理器缓存中找到,从而导致昂贵的外部内存访问。此外,与上面的链表示例类似,由于 table→dictEntry→...dictEntry→robj 序列中的地址是串行依赖的,因此在链中的前一个地址解析之前,无法确定下一个要访问的地址。
在足够大的键集上,搜索字典时访问的几乎每个内存地址都不会在任何处理器缓存中找到,从而导致昂贵的外部内存访问。此外,与上面的链表示例类似,由于 table→dictEntry→...dictEntry→robj 序列中的地址是串行依赖的,因此在链中的前一个地址解析之前,无法确定下一个要访问的地址。
批处理和交错
为了克服这种低效率,我们采用了以下方法。每当来自 I/O 线程的一批传入命令准备好执行时,Valkey 的主线程会在执行命令之前,高效地预取与这些命令相关的键在未来 lookupKey 调用中所需的内存地址。这个预取阶段通过 dictPrefetch 实现,它与上面链表示例类似,交错执行所有键的 table→dictEntry→...dictEntry→robj 搜索序列。这使 lookupKey 的时间减少了 80% 以上。我们还需要解决的另一个问题是,来自 I/O 线程的所有传入解析命令都不在运行 Valkey 主线程的核心的 L1/L2 缓存中。这也通过相同的方法解决了。所有相关代码都可以在 memory_prefetch.c 中找到。总的来说,内存访问分摊对 Valkey 性能的影响接近 50%,并将每秒请求数增加到超过 1.19M rps。
如何复现 Valkey 8.0 性能数据
本节将引导您了解复现我们性能结果的过程,我们使用 Valkey 8 实现了每秒 119 万个请求。
硬件设置
我们在 AWS EC2 c7g.4xlarge 实例上进行了测试,该实例具有基于 ARM (aarch64) 架构的 16 个核心。
系统配置
注意:本指南中使用的核心分配仅为示例。最佳核心选择可能因您的具体系统配置和工作负载而异。
中断亲和性 - 使用 ifconfig 定位网络接口(假设为 eth0)及其相关的 IRQ,通过
grep eth0 /proc/interrupts | awk '{print $1}' | cut -d : -f 1
在我们的设置中,48 到 55 行分配给 eth0 中断。每 4 条 IRQ 线分配一个核心
for i in {48..51}; do echo 1000 > /proc/irq/$i/smp_affinity; done
for i in {52..55}; do echo 2000 > /proc/irq/$i/smp_affinity; done
服务器配置 - 使用这些最小配置启动 Valkey 服务器
./valkey-server --io-threads 9 --save --protected-mode no
--save 禁用 RDB 文件转储,--protected-mode no 允许来自外部主机的连接。--io-threads 数包含主线程和 I/O 线程,这意味着在我们的案例中,除了主线程之外,还启动了 8 个 I/O 线程。
主线程亲和性 - 将主线程固定到特定的 CPU 核心,避开处理 IRQ 的核心。这里我们使用核心 #3
sudo taskset -cp 3 `pidof valkey-server`
重要提示:我们建议尝试不同的核心绑定策略,以找到最佳性能,同时避免与处理 IRQ 的核心发生冲突。
基准测试配置
从单独的实例运行基准测试,使用以下参数
- 值大小:512 字节
- 键数量:300 万
- 客户端数量:650
- 线程数量:50(为获得最佳结果可能会有所不同)
./valkey-benchmark -t set -d 512 -r 3000000 -c 650 --threads 50 -h "host-name" -n 100000000000
重要提示:运行基准测试时,可能需要几秒钟数据库才能填充并使性能稳定。您可以调整
-n参数以确保基准测试运行足够长时间以达到最佳吞吐量。
测试与可用性
Valkey 8.0 RC2 现已发布,可用于评估 I/O 线程和内存访问分摊功能。