
在树莓派上突破 Valkey 的极限
虽然在树莓派上进行大量性能测试很荒谬,但这让我意识到了性能测试的复杂性。例如,在下面的一些测试中,我最终设法用尽了树莓派的所有资源,导致性能表现糟糕。每个应用程序都有不同的性能特征,因此我们将探讨在部署 Valkey 时需要考虑哪些因素。
测试环境

硬件方面,我们将使用树莓派 Compute Module 4 (CM4)。它是一款单板计算机 (SBC),配备一块微小的 1.5Ghz 四核 Broadcom CPU 和 8GB 系统内存。这绝不是人们选择生产系统时的首选设备。使用 CM4 可以轻松展示如何根据不同的硬件限制来优化 Valkey。
我们的操作系统将是基于 Debian 的 64 位操作系统 (OS),名为 Rasbian。此发行版经过专门修改,可在 CM4 上良好运行。Valkey 将在由 docker compose 编排的 Docker 容器中运行。我喜欢在容器中部署,因为它简化了操作。如果您想跟着操作,这里是Docker 安装指南。请务必继续阅读安装过程的第二页。这很容易被忽略,跳过它可能会让您难以跟上。
我们将使用两台 CM4 进行测试。第一台将承载 Valkey,第二台将承载基准测试软件。这种设置可能更能反映大多数人在生产环境中的运行方式。基准测试使用 redis-benchmark 完成,因为它可以通过 sudo apt install redis-tools 安装。Valkey 确实有自己的基准测试工具,随 Valkey 一起安装。要改用 valkey-benchmark,您需要将 Valkey 安装在基准测试服务器上,或者启动一个容器并连接到其中。从功能上讲,在本文撰写时,它们的操作几乎相同。
设置我们的环境
下面是一个简单的 docker compose 文件,它将启动一个 Valkey 容器。此容器将 Valkey 绑定到主机设备的 6379 端口。这意味着它向任何可以访问您网络的人公开!这对于我们从基准测试服务器访问它很重要。
# valkey.yaml
services:
valkey-1:
image: valkey/valkey:latest
hostname: valkey1
command: valkey-server --port 6379 --requirepass ${VALKEY_PASSWORD} --io-threads ${IO_THREADS} --save ""
volumes:
- ./data:/data
network_mode: host
volumes:
data:
driver: local
由于我们将其暴露给内部网络,我们将为默认用户创建一个密码。我使用 head -16 /dev/urandom | openssl sha1 生成了一个随机密码。由于 Valkey 处理请求的速度很快,暴力破解攻击每秒可能尝试数十万个密码。生成该密码后,我将其放入与 docker compose 相同的目录中的 .env 文件中。
#.env
VALKEY_PASSWORD=e41fb9818502071d592b36b99f63003019861dad
NODE_IP=<VALKEY SERVER IP>
IO_THREADS=1
现在,通过运行 docker compose -f valkey.yaml up -d,Valkey 服务器将以我们设置的密码启动!
基线测试
现在我们准备进行一些基线测试。我们将登录到基准测试服务器。如果您尚未安装 redis-benchmark,可以使用 sudo apt install redis-tools 进行安装。
redis-benchmark -n 1000000 -t set,get -P 16 -q -a <PASSWORD FROM .env> --threads 5 -h 10.0.1.136
测试分解
-n- 这将使用-t中的命令运行 1,000,000 次操作-t- 将运行 set 和 get 测试-P- 这指定我们希望测试使用 16 个管道(每次请求发送 16 个操作)。-q- 静默输出,只显示最终结果-a- 使用指定的密码-h- 对指定的主机运行测试--threads- 生成测试数据所需的线程数
说实话,我对我得到的第一组结果感到震惊。当然,我预料 Valkey 会很快,但从一个单板计算机上获得这样的速度??而且还是单线程的??太棒了。
redis-benchmark -n 1000000 -t set,get -P 16 -q -a e41fb9818502071d592b36b99f63003019861dad --threads 5 -h 10.0.1.136
SET: 173040.33 requests per second, p50=4.503 msec
GET: 307031.00 requests per second, p50=2.455 msec
两次测试的平均值为每秒 24 万个请求。
提高 CPU 时钟速度
由于 Valkey 是一个单线程应用程序,因此更高的时钟速度会带来更高的性能。我预计大多数人不会在生产环境中对服务器进行超频。但可能会有不同 CPU 时钟速度的服务器可用。
注意: 时钟速度通常只适用于架构相似的 CPU 之间进行比较。例如,你可以合理地比较第 12 代 Intel i5 和第 12 代 Intel i7 之间的时钟速度。如果第 12 代 i7 的最大时钟速度为 5Ghz,这并不一定意味着它会比时钟频率为 5.6Ghz 的 AMD Ryzen 9 9900X 慢。
如果您正在自己的树莓派上操作,我已在下面列出了对 CM4 进行超频的步骤。否则,您可以跳到下面的结果部分。
警告 提醒您,对设备进行超频可能会损坏您的设备。请谨慎操作,并自行研究安全设置。
- 打开以下文件
sudo nano /boot/firmware/config.txt
- 在文件末尾的
[all]标签下添加以下部分[all] over_voltage=8 arm_freq=2200 - 重启树莓派并重新登录
sudo restart now
通过将时钟速度从 1.5Ghz 提高到 2.2Ghz,我们刚刚将树莓派的速度提高了 47%。现在让我们重新运行测试,看看情况如何!
redis-benchmark -n 1000000 -t set,get -P 16 -q -a e41fb9818502071d592b36b99f63003019861dad --threads 5 -h 10.0.1.136
SET: 394368.41 requests per second, p50=1.223 msec
GET: 438058.53 requests per second, p50=1.135 msec
我们达到了每秒 41.6 万个请求(提醒一下,这是两次操作的平均值)。数学家们可能会注意到,这种速度提升远高于预期的 47% 增长。每秒请求量增加了 73%。发生了什么?!
添加 IO 线程
有了这些提升,我非常兴奋地尝试 Valkey 8 中新的IO 线程功能。首先,我们将使用 docker compose -f valkey.yaml down 停止之前运行的 Docker 实例。然后,我们将修改 .env 文件的 IO_THREADS 参数为 5。
#.env
VALKEY_PASSWORD=e41fb9818502071d592b36b99f63003019861dad
NODE_IP=<VALKEY SERVER IP>
IO_THREADS=5
然后我们可以 docker compose -f valkey.yaml up -d 再次启动它。远程连接到基准测试服务器开始测试,然后呢……?
redis-benchmark -n 10000000 -t set,get -P 16 -q -a e41fb9818502071d592b36b99f63003019861dad --threads 5 -h 10.0.1.136
SET: 345494.75 requests per second, p50=0.911 msec
GET: 327858.09 requests per second, p50=0.879 msec
等等……这些结果比之前的还差?我们从每秒 41.6 万个请求降到了 33.6 万个……发生了什么?
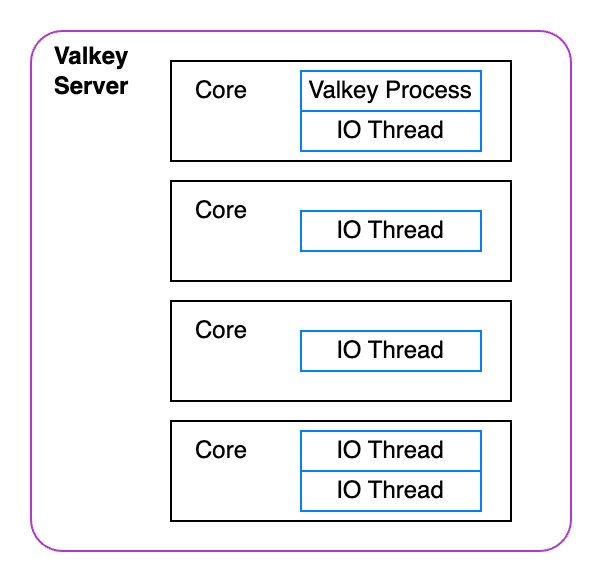
我们过度分配了 CPU。这意味着我们创建了比 CPU 核心更多的辅助线程。当一个线程持续负载时,它会与该核心上的其他线程竞争资源。更不用说,它们还在与 Valkey 进程竞争资源。
这就是为什么 Valkey 建议将线程数设置为小于您拥有的核心数的值。对于我们的小型 4 核服务器,让我们将 .env 文件中的 IO_THREADS 参数更改为 2 个线程,然后重试。
redis-benchmark -n 10000000 -t set,get -P 16 -q -a e41fb9818502071d592b36b99f63003019861dad --threads 5 -h 10.0.1.136
SET: 609050.44 requests per second, p50=0.831 msec
GET: 521186.22 requests per second, p50=0.719 msec
好多了!现在我们看到了每秒约 56.5 万个请求。这意味着两项指标的性能都提升了 35%!更不用说在下面的图片中,您可以看到我们所有 CPU 的利用率都达到了 100%,这意味着没有进一步改进的空间了!
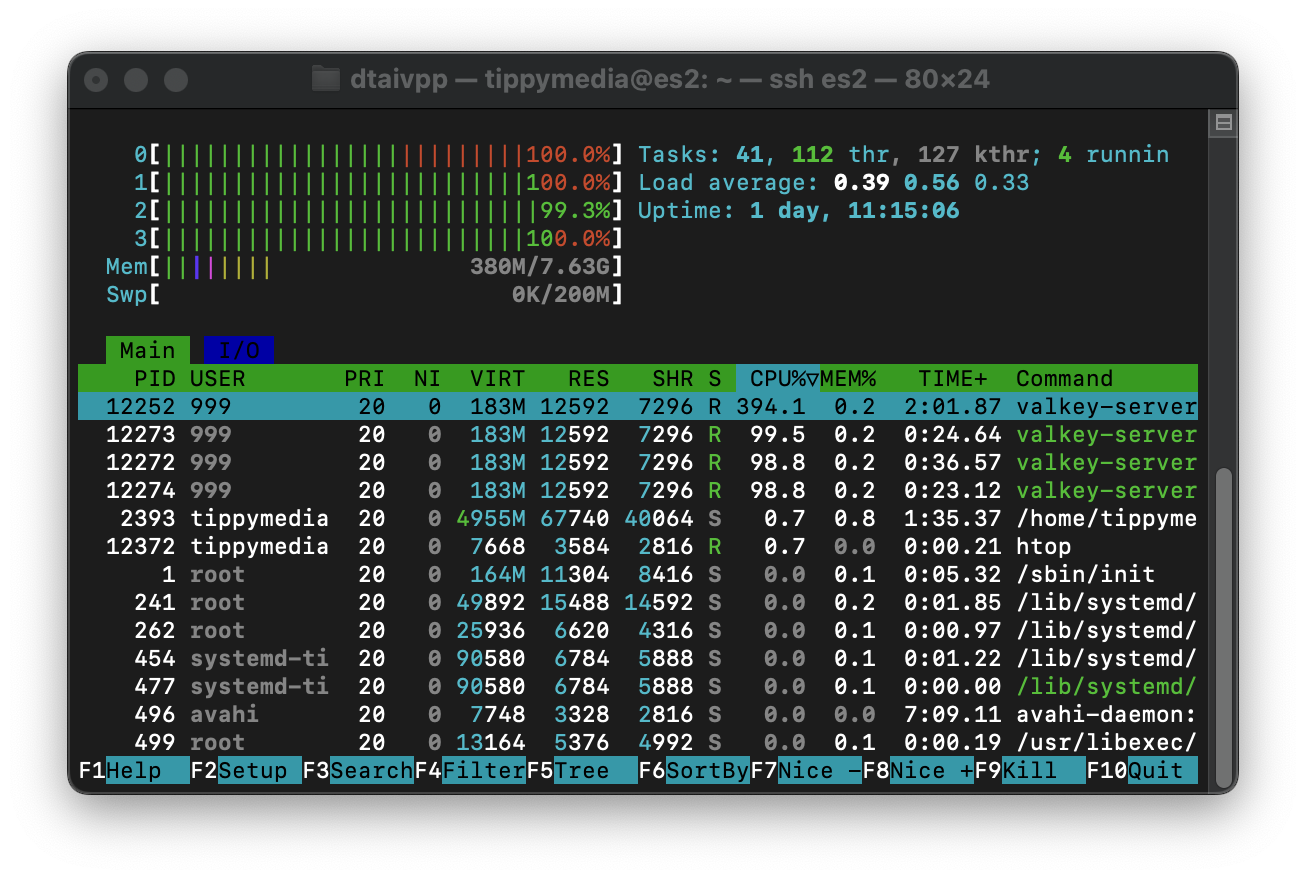
是吗?信不信由你,我们的小 CM4 还能榨出更多性能!
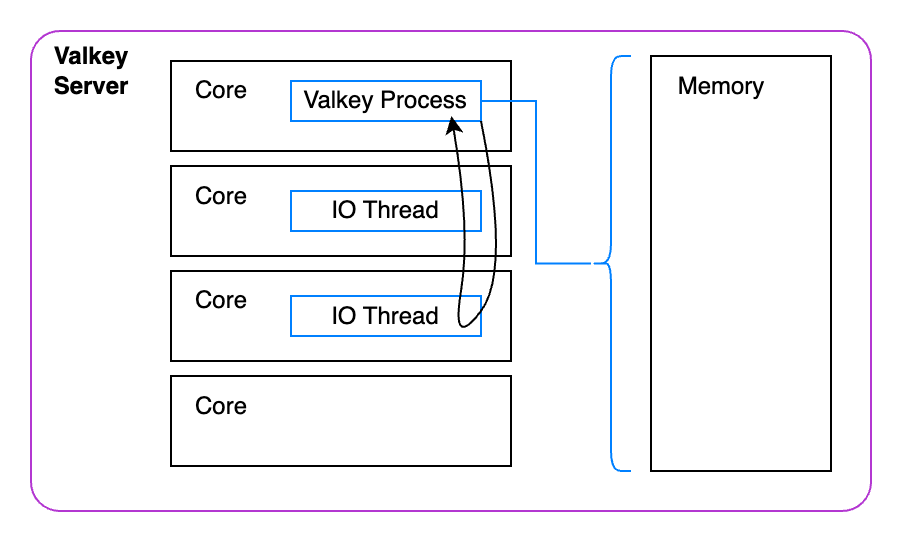
上面是服务器上发生情况的代表性概览。Valkey 进程必须占用宝贵的周期来管理 IO 线程。不仅如此,它还需要执行大量工作来管理分配给它的所有内存。对于单个进程来说,这工作量很大。
现在,实际上还有一项优化可以使单线程 Valkey 更快。Valkey 最近在支持推测执行方面做了大量工作。这项工作允许 Valkey 预测在未来的处理步骤中需要从内存中获取哪些值。这样,Valkey 服务器就不必等待内存访问,因为内存访问比 L1 缓存慢一个数量级。虽然我不会详细介绍其工作原理,因为已经有一篇很棒的博客文章描述了如何利用这些优化。以下是结果:
redis-benchmark -n 10000000 -t set,get -P 16 -q -a e41fb9818502071d592b36b99f63003019861dad --threads 5 -h 10.0.1.136
SET: 632791.25 requests per second, p50=1.191 msec
GET: 888573.00 requests per second, p50=0.695 msec
虽然这些结果更好,但有点令人困惑。在与 Valkey 的一些维护者交流后,似乎 Rasbian 在内存写入方面可能有一些不同的配置。在他们的测试中,GET/SET 请求几乎相同,但到目前为止我的测试中,写入速度似乎总是落后于读取速度。如果您知道原因,请联系我们!
集群 Valkey
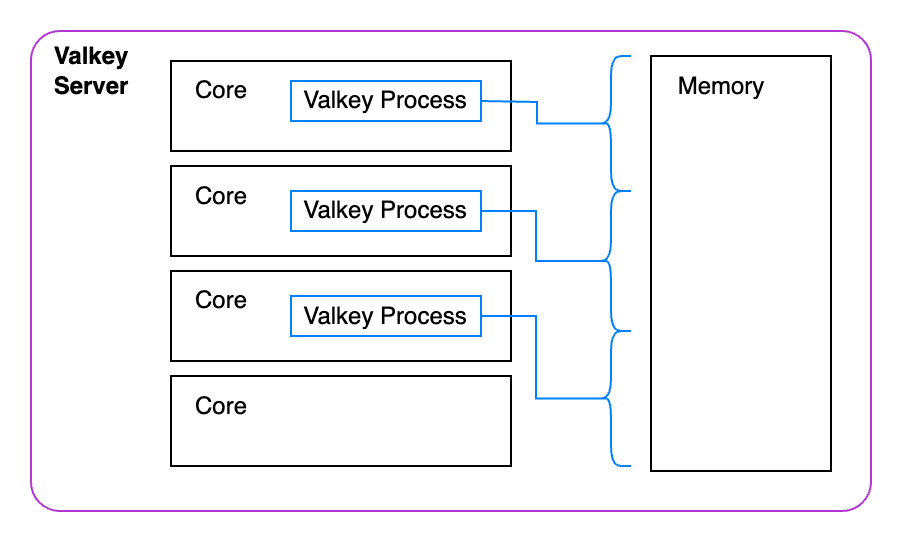
最后一步,我们将启动一个 Valkey 集群。这个集群将运行独立的 Valkey 实例,每个实例将负责管理自己的键。这样,每个实例可以更容易地并行执行操作。
我不会详细介绍键空间的工作原理,但这里有一个很好的 101 指南,可帮助您理解 Valkey 中的集群。
首先,我们将停止之前的 Valkey 容器 docker compose -f valkey.yaml down。现在我们可以为集群创建 docker compose 文件。由于这些都暴露在主机上,它们都需要使用不同的端口。此外,它们都需要知道它们是在集群模式下启动的,这样它们才能将请求重定向到适当的实例。
# valkey-cluster.yaml
services:
valkey-node-1:
hostname: valkey1
image: valkey/valkey:latest
command: valkey-server --port 6379 --cluster-enabled yes --cluster-config-file nodes.conf --cluster-node-timeout 5000 --requirepass ${VALKEY_PASSWORD} --save ""
volumes:
- ./data1:/data
network_mode: host
valkey-node-2:
hostname: valkey2
image: valkey/valkey:latest
command: valkey-server --port 6380 --cluster-enabled yes --cluster-config-file nodes.conf --cluster-node-timeout 5000 --requirepass ${VALKEY_PASSWORD} --save ""
volumes:
- ./data2:/data
network_mode: host
valkey-node-3:
hostname: valkey3
image: valkey/valkey:latest
command: valkey-server --port 6381 --cluster-enabled yes --cluster-config-file nodes.conf --cluster-node-timeout 5000 --requirepass ${VALKEY_PASSWORD} --save ""
volumes:
- ./data3:/data
network_mode: host
volumes:
data1:
driver: local
data3:
driver: local
data2:
driver: local
运行 docker compose -f valkey-cluster.yaml up -d 启动集群。集群运行还需要一个步骤。使用 docker ps --format '{{.Names}}' 找到其中一个节点的名称。
docker ps --format '{{.Names}}
kvtest-valkey-node-1-1
kvtest-valkey-node-3-1
kvtest-valkey-node-2-1
我将使用第一个容器来完成集群的创建。一旦容器启动,我们必须告诉它们集群所需的详细信息。下面我正在使用主机的 IP 和所有容器的端口配置来创建集群。这是因为这些地址需要可以从基准测试服务器访问。
docker exec -it kvtest-valkey-node-1-1 valkey-cli --cluster create 10.0.1.136:6379 10.0.1.136:6380 10.0.1.136:6381 -a e41fb9818502071d592b36b99f63003019861dad
现在我们可以运行我们的基准测试了!我们需要在基准测试命令中添加 --cluster 标志。此外,由于速度很快,我最终将请求从 100 万次增加到 1000 万次。这样我们可以确保 Valkey 有足够的时间充分利用其所有资源。
redis-benchmark -n 10000000 -t set,get -P 16 -q --threads 10 --cluster -a e41fb9818502071d592b36b99f63003019861dad --threads 5 -h 10.0.1.136
Cluster has 3 master nodes:
Master 0: 219294612b44226fa32482871cf21025ff531875 10.0.1.136:6380
Master 1: e5d85b970551c27065f1552f5358f4add6114d98 10.0.1.136:6381
Master 2: 1faf3d0dd22e518eec11fd46c0de6ce18cd15cfe 10.0.1.136:6379
SET: 1122838.50 requests per second, p50=0.575 msec
GET: 1188071.75 requests per second, p50=0.511 msec
每秒 1,155,000 个请求。我们成功地将每秒请求量翻了一番。所有这些都在一个信用卡大小的单板计算机上实现。
虽然这远非我推荐用于生产服务器的配置,但这些是我会推荐给评估 Valkey 的人的相同步骤。重要的是从单个实例开始测试,以找到最佳设置。然后,您可以通过添加更多 IO 线程或 Valkey 实例来扩大测试规模。
测试应尽可能反映您的生产工作负载。本测试使用合成数据。因此,我建议查阅文档,以了解您可能需要测试的其他设置。例如,我们使用默认设置进行了测试:50 个客户端连接和 3 字节有效负载。您的生产工作负载可能有所不同,因此请探索所有设置!您可能会发现 IO 线程比我在本例中更适合您的用例。
如果您喜欢这篇文章,请务必查看我的博客 TippyBits.com,我会在那里定期发布此类内容。保持好奇,我的朋友们!