
新型哈希表
许多工作负载都受限于数据存储。能够使用更少的内存存储更多数据,可以帮助您减小集群规模。
在 Valkey 中,键和值存储在所谓的哈希表中。哈希表的工作原理是将一个键切分成若干看似随机的位。这些位被构造成一个内存地址,指向值应存储的位置。这是一种无需扫描所有键就能直接跳到内存中正确位置的非常快速的方法。
为了 8.1 版本,我们研究了如何提高性能和内存使用率,以便用户可以使用更少的内存存储更多数据。这项工作促使我们设计了一种新型哈希表,但首先,让我们看看 Valkey 到目前为止使用的哈希表。
字典(dict)
Valkey 至今使用的哈希表,名为“dict”,其内存布局如下
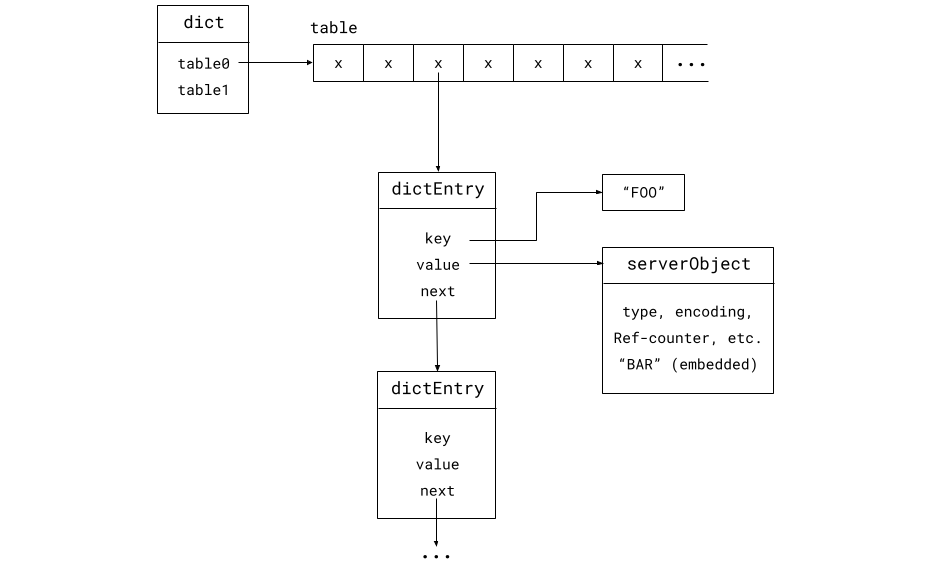
该 dict 有两个表,分别称为“表 0”和“表 1”。通常只有一个表存在,但在进行增量重新哈希时会同时使用这两个表。
它是一个链式哈希表,因此如果多个键哈希到表中的同一个槽位,它们的键值对条目会形成一个链表。这就是 dictEntry 中“next”指针的作用。
要查找键“FOO”并访问值“BAR”,Valkey 仍需要从内存中读取四次。如果发生哈希冲突,它必须为每个哈希冲突多跟随两个指针,因此需要从内存中多读取两次(键和下一个指针)。
最小化内存访问
查找键值对时较慢的操作之一是从主内存(RAM)读取。因此,关键是要确保我们进行尽可能少的内存访问。理想情况下,我们想要访问的内存应该已经加载到 CPU 缓存中,CPU 缓存是 CPU 拥有的一个更小但快得多的内存。
为了优化内存使用,我们还希望最小化独立内存分配的数量以及它们之间的指针数量,因为在 64 位系统中存储一个指针需要 8 字节。如果我们每个键值对可以节省一个指针,那么对于一亿个键来说,这几乎是一个千兆字节。
当 CPU 将数据从主内存加载到 CPU 缓存时,它以固定大小的块(称为缓存行)进行。在几乎所有现代硬件上,缓存行的大小都是 64 字节。最近关于哈希表的研究,例如 Swiss tables,经过高度优化,可以在单个缓存行内存储和访问数据。如果您要查找的键在首次查找的位置(由于哈希冲突)未找到,那么理想情况下它应该在同一缓存行内找到。如果是这样,一旦该缓存行加载到 CPU 缓存中,查找速度就会非常快。
所需特性
为什么不使用 Swiss tables 等开源的、最先进的哈希表实现呢?答案是除了添加、查找、替换和删除等基本操作之外,我们还需要一些特定功能
-
增量重新哈希,以便当哈希表已满时,在表调整大小时不会冻结服务器。
-
扫描,一种即使哈希表在迭代之间调整大小也能遍历哈希表的方式。这对于继续支持 SCAN 命令非常重要。
-
随机元素采样,用于像 RANDOMKEY 这样的命令。
这些不是标准功能,所以我们不能简单地选择一个现成的哈希表。我们必须自己设计一个。
设计
在为 Valkey 8.1 设计的新型哈希表中,表由 64 字节的桶组成,每个桶就是一个缓存行。每个桶最多可以存储七个元素。映射到同一个桶的键都存储在同一个桶中。桶还包含一个元数据部分,在图中标记为“m”。包括元数据部分在内的桶布局将在下面详细解释。
我们取消了 dictEntry,而是将键和值以及键的其他数据嵌入到 serverObject 中。

假设 hashtable 结构已在 CPU 缓存中,现在查找键值条目只需要两次内存查找:桶和 serverObject。如果发生哈希冲突,我们要查找的对象很可能在同一个桶中,因此无需额外的内存访问。
如果一个桶变满,桶中最后一个元素槽位会被一个指向子桶的指针替换。子桶的布局与常规桶相同,但它是独立分配的。这些桶链的长度没有限制,但只要键通过哈希函数分布良好,长链就非常罕见。大多数键都存储在顶层桶中。
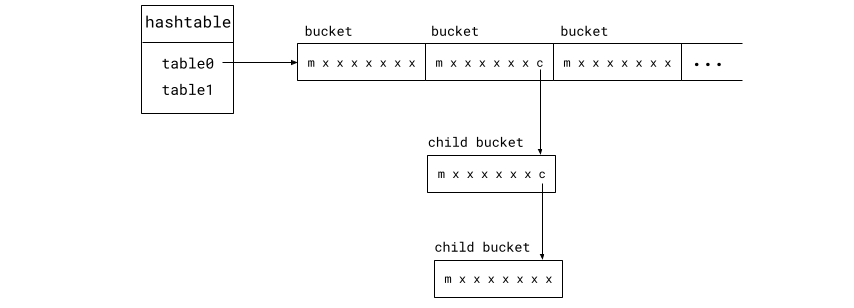
同一桶或桶链中的元素存储时没有任何内部排序。向桶中插入新条目时,可以使用任何空闲槽位。
如前所述,每个桶还包含一个元数据部分。桶元数据由八个字节组成,其中一个位指示桶是否具有子桶。接下来的七个位,每个位对应七个元素槽位中的一个,指示该槽位是否已填充,即是否包含一个元素。剩余的七个字节用于为桶中存储的每个条目存储一个字节的二级哈希值。

二级哈希由查找桶时未使用的哈希位组成。在一个 64 位的哈希值中,我们查找桶不需要超过 56 位,我们使用剩余的 8 位作为二级哈希。这些哈希位用于在查找键时无需比较键即可快速排除不匹配的条目。比较桶中每个条目的键将需要每个条目一次额外的内存访问。如果二级哈希与我们正在查找的键不匹配,我们可以立即跳过该条目。误报的几率,即二级哈希匹配但条目与我们正在查找的键不匹配的几率是 256 分之一,因此这消除了 99.6% 的误报。
结果
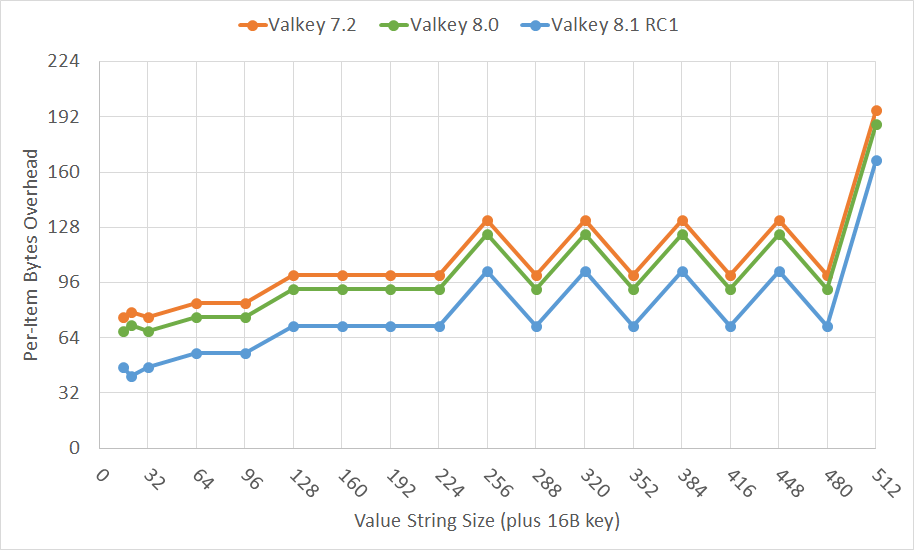
通过用不同的实现替换哈希表,我们成功地将每个键值对的内存使用量减少了大约 20 字节。
下图显示了不同值大小的内存开销。开销是不包括键和值本身的内存使用量。越低越好。(锯齿形模式是由于内存分配器离散分配大小导致未使用的内存。)
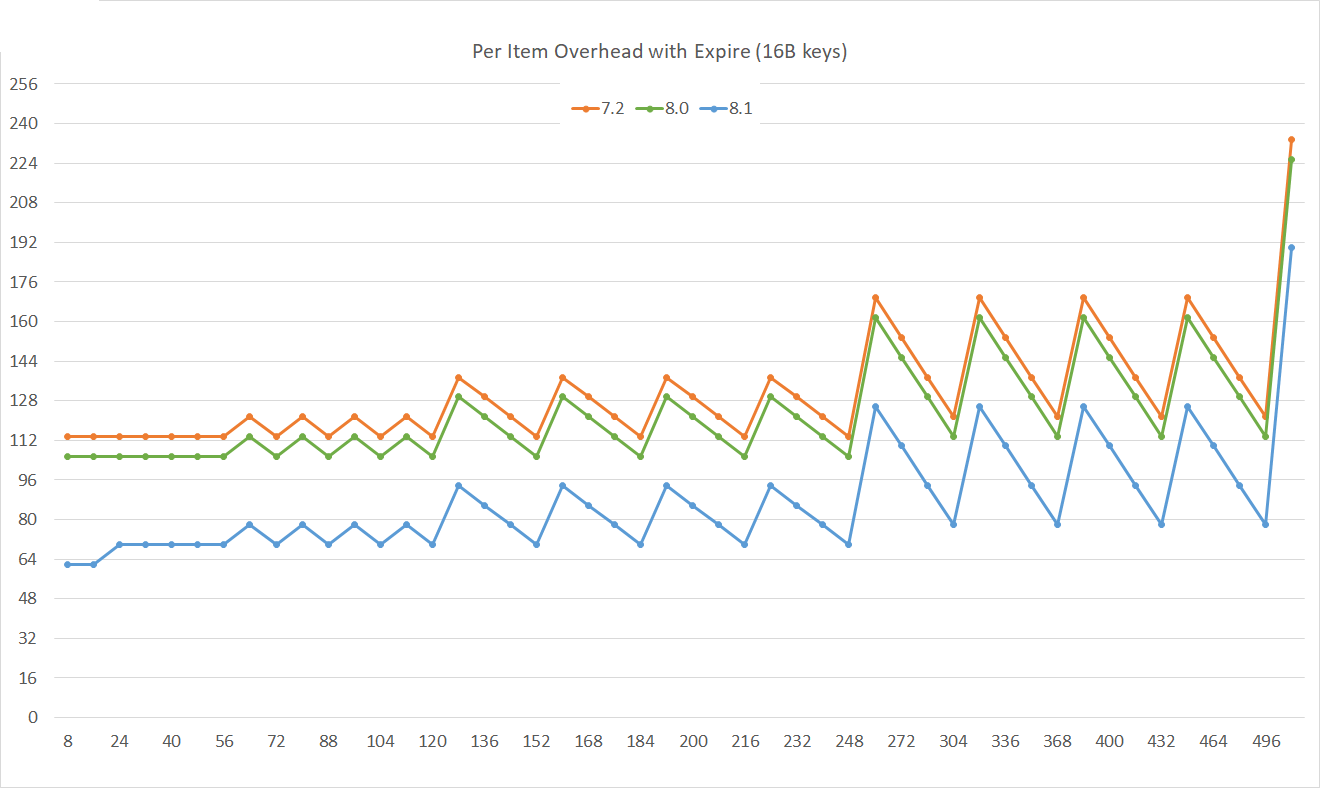
对于带有 过期时间(生存时间,TTL)的键,内存使用量进一步减少,每个键值对大约减少 30 字节。
在某些工作负载中,例如存储非常小的对象和广泛使用管道时,延迟和 CPU 使用率也得到了改善。但在大多数情况下,这在实践中可以忽略不计。主要收获似乎是内存使用量的减少。
哈希(Hashes)、集合(sets)和有序集合(sorted sets)
嵌套数据类型哈希、集合和有序集合在包含足够多的元素时也利用了新型哈希表。对于这些类型的键,每个元素的内存使用量大约减少 10-20 字节。
特别感谢 Rain Valentine 提供的图表以及在将此哈希表集成到 Valkey 中所提供的帮助。