
Valkey 布隆过滤器介绍
Valkey 项目正在通过 valkey-bloom(BSD-3 许可)引入布隆过滤器作为一种新的数据类型,这是一个官方 Valkey 模块,兼容 Valkey 8.0 及更高版本。布隆过滤器提供高效的大规模成员测试,提高性能并为高并发应用节省大量内存。
例如,为了处理广告去重工作负载并回答“此客户之前是否看过此广告?”的问题,Valkey 开发者可以使用 SET 数据类型。这可以通过将客户 ID(看过广告的客户)添加到代表特定广告的 SET 对象中来完成。然而,这种方法的问题在于内存使用量高,因为集合中的每个项目都会被分配内存。本文将演示如何使用 valkey-bloom 中的布隆过滤器数据类型实现显著的内存节省,在我们的示例工作负载中超过 93%,同时探讨其实现、技术细节和实际建议。
简介
布隆过滤器是一种空间高效的概率数据结构,支持添加元素和检查元素是否已添加。可能出现误报(false positive),即过滤器错误地指示元素存在,即使它从未被添加。然而,布隆过滤器保证不会出现漏报(false negative),这意味着成功添加的元素永远不会被报告为不存在。
 图片来源:source
图片来源:source
{kind=link}
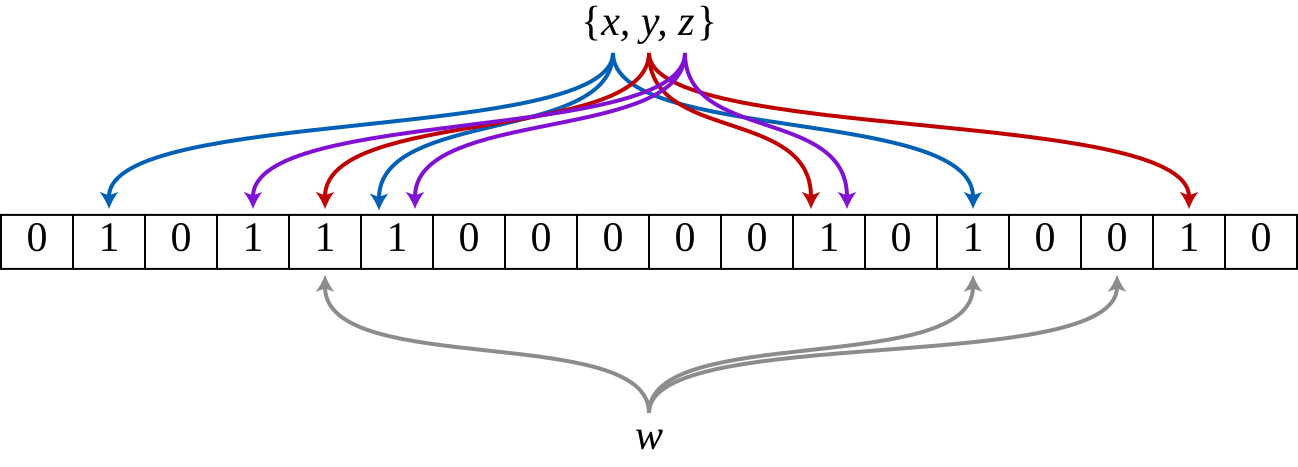
当向布隆过滤器添加项时,K 个不同的哈希函数从位向量中计算出 K 个对应的位,然后将其设置为 1。检查是否存在涉及相同的哈希函数——如果任何位为 0,则该项肯定不存在;如果所有位都为 1,则该项可能存在(具有定义的误报概率)。这种基于位的 S 方法,而不是完整的项分配,使得布隆过滤器在空间上非常高效,但代价是潜在的误报。
Valkey-Bloom 将布隆过滤器作为一种新的数据类型引入 Valkey,提供了可伸缩和不可伸缩两种变体。它与官方 Valkey 客户端库(包括 valkey-py, valkey-java, valkey-go)以及等效的 Redis 库的布隆过滤器命令语法兼容。
数据类型概述
“布隆对象”是主要的布隆数据类型结构。它是通过任何布隆过滤器创建命令创建的,并且此结构可以根据用户配置充当“可伸缩布隆过滤器”或“不可伸缩布隆过滤器”。在可伸缩的情况下,它包含一个长度大于等于 1 的“子过滤器”向量,而在不可伸缩的情况下则只包含 1 个。
“子过滤器”是在“布隆对象”内部创建和使用的内部结构。它跟踪容量、已添加的项目数量以及布隆过滤器实例(具有指定的属性)。
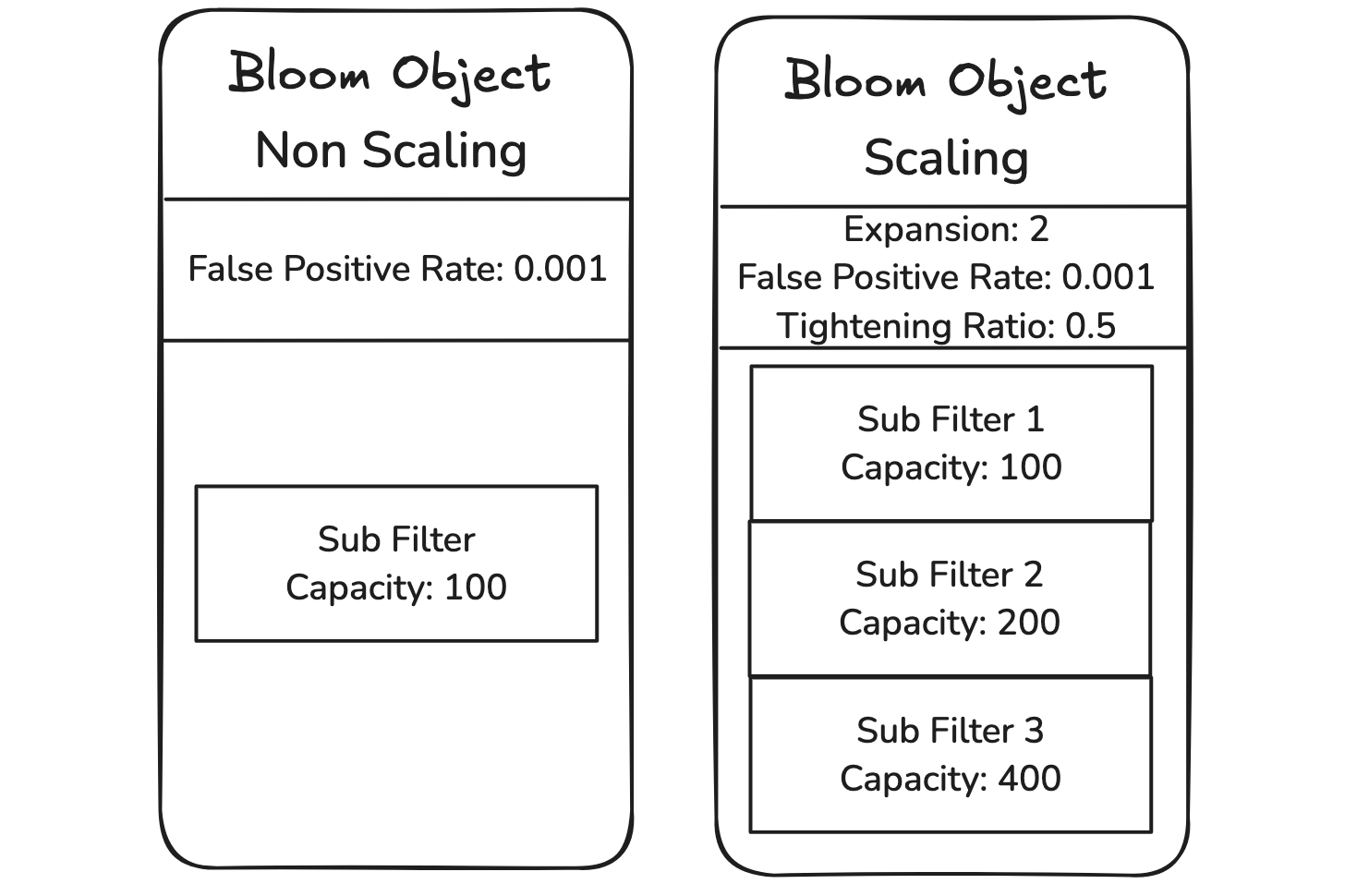
不可伸缩
当不可伸缩过滤器达到其容量时,如果用户尝试添加新的/唯一的项,则会返回错误。您可以使用 BF.RESERVE 或 BF.INSERT 命令创建不可伸缩布隆过滤器。示例
BF.RESERVE <filter-name> <error-rate> <capacity> NONSCALING
可伸缩
当可伸缩过滤器达到其容量时,如果用户向布隆过滤器添加项,则会创建一个新的子过滤器并将其添加到子过滤器向量中。这个新的布隆子过滤器将具有更大的容量(之前的布隆过滤器容量 * 布隆过滤器的扩展率)。当检查一个项是否存在于已扩展的布隆过滤器上时(BF.EXISTS/BF.MEXISTS),我们会在子过滤器向量中遍历每个过滤器(从最旧到最新)并对每个过滤器执行检查操作。类似地,要向布隆过滤器添加新项,我们会检查所有过滤器以查看该项是否已存在,如果不存在,则将该项添加到当前过滤器。通过 BF.ADD、BF.MADD、BF.INSERT 默认创建的任何过滤器都将是可伸缩布隆过滤器。
常见布隆过滤器属性
容量 (Capacity) - 在布隆过滤器发生扩容(对于可伸缩布隆过滤器)或任何插入新项的命令返回错误(对于不可伸缩布隆过滤器)之前,可以添加的唯一项的数量。
误报率 (FP) - 控制项目添加/存在操作产生误报的概率的速率。例如:0.001 意味着每 1000 次操作中可能有 1 次是误报。
用例 / 内存节省
在此示例中,我们模拟了布隆过滤器的一个非常常见的用例:广告去重。应用程序可以利用布隆过滤器来跟踪广告/促销是否已向客户展示过,并利用此功能防止再次向客户展示。
假设我们有 500 个独一无二的广告,我们的服务有 500 万客户。广告和客户都由 UUID(36 个字符)标识。
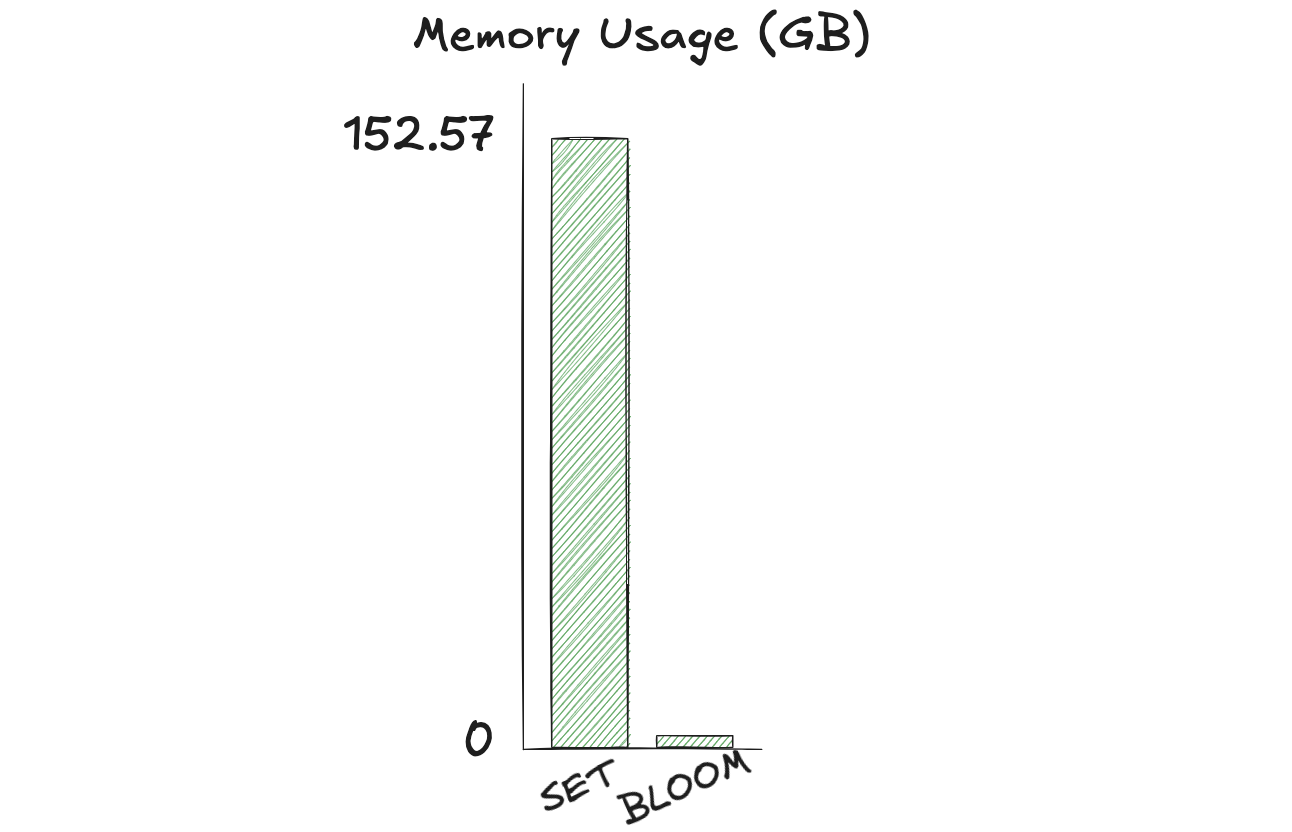
不使用布隆过滤器时,应用程序可以使用 SET Valkey 数据类型,这样每个广告都有一个唯一的 SET。然后,他们可以使用 SADD 命令将每个已看过特定广告的客户添加到集合中进行跟踪。要检查客户是否看过广告,可以使用 SISMEMBER 或 SMISMEMBER 命令。这意味着我们有 500 个集合,每个集合有 500 万成员。这将在 Valkey 8.0 服务器上占用约 152.57 GB 的 used_memory。
使用布隆过滤器时,应用程序可以使用 BF.RESERVE 或 BF.INSERT 命令为每个广告创建一个唯一的布隆过滤器。在这里,他们可以指定所需的精确容量:500 万——这意味着可以将 500 万项添加到布隆过滤器中。对于每个展示广告的客户,应用程序可以将客户的 UUID 添加到特定过滤器中。要检查客户是否看过广告,可以使用 BF.EXISTS 或 BF.MEXISTS 命令。因此,我们有 500 个布隆过滤器,每个容量为 500 万。这将根据误报率需要可变内存。在所有情况下(即使是更严格的误报率),与使用 SET 数据类型相比,我们可以看到显著的内存优化。
| 布隆过滤器数量 | 容量 | 误报率 (FP Rate) | 误报率说明 | 总已用内存 (GB) | 相较于 SETS 的内存节省百分比 |
|---|---|---|---|---|---|
| 500 | 5000000 | 0.01 | 百分之一 | 2.9 | 98.08% |
| 500 | 5000000 | 0.001 | 千分之一 | 4.9 | 96.80% |
| 500 | 5000000 | 0.00001 | 十万分之一 | 7.8 | 94.88% |
| 500 | 5000000 | 0.0000002 | 五百万分之一 | 9.8 | 93.60% |
在此示例中,与使用 SET 数据类型相比,使用布隆过滤器可以在内存使用方面节省 93% - 98%。根据您的工作负载,您可以预期类似的结果。
大型布隆过滤器和建议
为了提高布隆过滤器序列化和反序列化期间的服务器性能,我们为每个对象的内存使用添加了验证。布隆过滤器的默认内存使用限制由 BF.BLOOM-MEMORY-USAGE-LIMIT 配置定义,其默认值为 128 MB。但是,可以使用上述配置进行调整。
内存限制的含义是,涉及布隆过滤器创建或扩容的操作,如果导致布隆过滤器的总内存使用量超过限制,将返回错误。示例
127.0.0.1:6379> BF.ADD ad1_filter user1
(error) ERR operation exceeds bloom object memory limit
这给用户带来了问题,他们的可伸缩布隆过滤器在数据填充几天后可能会达到内存限制,并在插入唯一项时开始出现扩容失败。
作为解决方案,为了帮助用户了解他们的布隆过滤器在何种容量下会达到内存限制,valkey-bloom 提供了两个选项。这些选项在事先检查以确保您的布隆过滤器不会在工作负载中后期出现扩容或创建失败时非常有用。
- 在创建布隆过滤器之前执行内存检查
我们可以使用 BF.INSERT 命令的 VALIDATESCALETO 选项来验证过滤器是否在内存限制内。如果不在限制内,命令将返回错误。在下面的示例中,我们看到 filter1 由于内存限制无法扩容并达到 26214301 的容量。但是,它可以扩容并达到 26214300 的容量。
127.0.0.1:6379> BF.INSERT filter1 VALIDATESCALETO 26214301
(error) ERR provided VALIDATESCALETO causes bloom object to exceed memory limit
127.0.0.1:6379> BF.INSERT filter1 VALIDATESCALETO 26214300 ITEMS item1
1) (integer) 1
- 检查现有可伸缩布隆过滤器可扩展到的最大容量
我们可以使用 BF.INFO 命令来找出可伸缩布隆过滤器可以扩展到的最大容量。在这种情况下,我们可以看到该过滤器可以容纳 26214300 个项目(在扩容达到内存限制后)。
127.0.0.1:6379> BF.INFO filter1 MAXSCALEDCAPACITY
(integer) 26214300
为了了解单个不可伸缩过滤器的最大容量的内存使用情况,我们有下表。在 128MB 限制和默认误报率下,我们可以创建一个容量为 1.12 亿的布隆过滤器。在 512MB 限制下,布隆过滤器可以容纳 4.48 亿个项目。
| 不可伸缩过滤器 - 容量 | 误报率 (FP Rate) | 内存使用 (MB) | 备注 |
|---|---|---|---|
| 1.12亿 | 0.01 | ~128 | 默认误报率和默认内存限制 |
| 7400万 | 0.001 | ~128 | 自定义误报率和默认内存限制 |
| 4.48亿 | 0.01 | ~512 | 默认误报率和自定义内存限制 |
| 2.98亿 | 0.001 | ~512 | 自定义误报率和自定义内存限制 |
性能
涉及添加项目或检查项目是否存在的布隆命令的时间复杂度为 O(N * K),其中 N 是插入的元素数量,K 是布隆过滤器使用的哈希函数数量。这意味着 BF.ADD 和 BF.EXISTS 都只有 O(K) 的时间复杂度,因为它们只操作一个项目。
在可伸缩布隆过滤器中,每次扩容时,添加/存在操作期间基于哈希函数的检查数量都会增加;每个子过滤器至少需要一个哈希函数,并且随着误报率因 紧缩比率 而在扩容时变得更严格,这个数量也会增加。因此,建议用户在评估用例/工作负载后选择容量和扩展率,以避免多次扩容并减少检查次数。
示例:要使一个布隆过滤器以 10 万的起始容量和 1 的扩展率达到 1000 万的总容量,它将需要 100 个子过滤器(在 99 次扩容后)。相反,如果起始容量相同(10 万)且扩展率为 2,一个布隆过滤器只需 7 个子过滤器即可达到约 1270 万的总容量。或者,在扩展率为 1、起始容量为 100 万的情况下,一个布隆过滤器可以通过 10 个子过滤器达到 1000 万的总容量。这两种方法都显著减少了每次项目添加/存在操作的检查次数。
其他布隆过滤器命令的时间复杂度为 O(1):BF.CARD、BF.INFO、BF.RESERVE 和 BF.INSERT(未提供项目时)。
结论
valkey-bloom 通过布隆过滤器为高容量成员测试提供了高效的解决方案,与传统数据类型相比,显著节省了内存使用。这增强了 Valkey 处理各种工作负载的能力,包括大规模广告/事件去重、欺诈检测以及更有效地减少磁盘/后端查询。
要了解更多关于 valkey-bloom 的信息,您可以阅读 布隆过滤器数据类型,并按照快速入门指南亲自尝试。此外,要在 Docker 上使用 valkey-bloom(以及其他官方模块),您可以查看 Valkey Extensions Docker 镜像。
感谢所有帮助开发此模块的人员
- Karthik Subbarao (KarthikSubbarao)
- Cameron Zack (zackcam)
- Vanessa Tang (YueTang-Vanessa)
- Nihal Mehta (nnmehta)
- wuranxx (wuranxx)